CHDICT’s initial release in numbers
The easiest way to describe a dictionary is to say that it has 10,888 Chinese headwords and 24,554 Hungarian senses. That’s precisely the extent of CHDICT at the time of its initial release in May 2017. Driven by my own curiosity, I also calculated a few additional statistics, which I’m sharing below.
Coverage and word frequencies
I took the top 40 thousand words from SUBTLEX-CH’s frequency list and cross-checked how many of each 1000-word bucket from the ranked list is there in CHDICT. These are the red data points in the plot below. For comparison I also calculated the coverage of CC-CEDICT, a mature dictionary with 110 thousand headwords; these values are shown in blue.
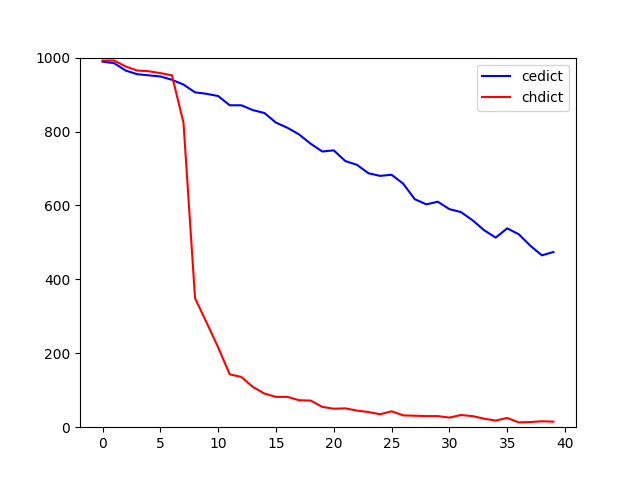
You can see that CHDICT has nearly 100% coverage for the top 6,000 words: for each 1000-word bucket, almost 1000 words are there in the dictionary. This is not surprising; after all, I defined the scope by plucking the top of exactly this frequency list.
Beyond this range CHDICT’s coverage falls sharply. The cut-off point is well below 10 thousand words; conversely, CHDICT’s 11 thousand headwords include many words from lower frequency ranges. The reason for this is that I included the 6 thousand required words for the HSK exams without regard to their frequency rank, and HSK’s compilers apparently did not focus on the most common colloquial vocabulary.
Curiously, CC-CEDICT’s coverage also shows a steady decline. I wrote two related texts about that, which you can read here and here. It is not at all clear what, exactly, constitutes a language’s vocabulary, and we will get as many different answers as there are sources to consult.
Labels
The dictionary uses no more than 18 different labels. (By label I mean the optional meta-information in parantheses at the start of senses.) Below are the extracted labels, with the number of times they are used.
236 családnév 141 átirat 130 kifejezés 127 földrajzi név 127 számlálószó 34 tulajdonnév 13 rövidítés 10 szleng 9 indulatszó 9 átvitten 8 hangutánzó 7 vulgáris 6 szó szerint 3 toldalék 3 köznyelvi 2 tabu 2 nyelvjárási 1 cím
Hungarian word forms
The 24,554 senses contain a total of 13,389 different Hungarian word forms and chunks. (Chunks are parts of a full word where a verbal particle or a compound is delimited with a | character.) The top 50 tokens, along with their frequency in CHDICT’s senses:
1005 meg 56 fog 695 el 53 ember 581 ki 51 hagy 392 fel 49 lép 271 be 48 hely 271 le 48 magát 225 a 47 minden 188 össze 46 állít 171 nem 43 csak 152 át 42 ér 146 van 42 néz 125 és 41 előre 121 az 41 mint 112 ad 41 hoz 104 vesz 41 tér 96 tesz 40 vezet 88 vissza 39 rá 87 megy 37 idő 79 tart 37 erő 78 hogy 37 bele 67 áll 37 még 64 elő 37 nő 62 nagy 37 köt 58 egy 36 pont 56 jó 36 visz
The most frequent tokens act as stopwords in Hungarian searches: the website only returns entries where they make up a full sense. As an end user I would have little benefit from 171 results for a frequent word like “nem” (Hungarian for “no”) - results where “nem” occurs somewhere in a longer sense.
Numerical classifiers
CHDICT’s initial release has a numerical classifier for 983 words (occasionally more than one). There are 123 different classifiers in the data. The list below shows the top 20 classifiers, along with their frequency in CHDICT (showing only simplified characters here):
444 个 25 片 56 条 23 根 55 只 23 份 41 位 22 块 37 张 22 件 36 次 21 种 29 把 20 部 27 场 20 颗 27 家 19 项 25 座 18 间
Ambiguity, word length and frequency
We intuitively feel that shorter words tend to be the more frequent ones, and also that short and frequent words tend to have many meanings, or meanings that are difficult to map to non-Chinese words.
Does the dictionary confirm this perception? The plot below, once again, projects CHDICT’s headwords onto the ranked frequency list, and shows the average number of senses per entry and headwords’ average syllable count in each bucket of 1000 words.
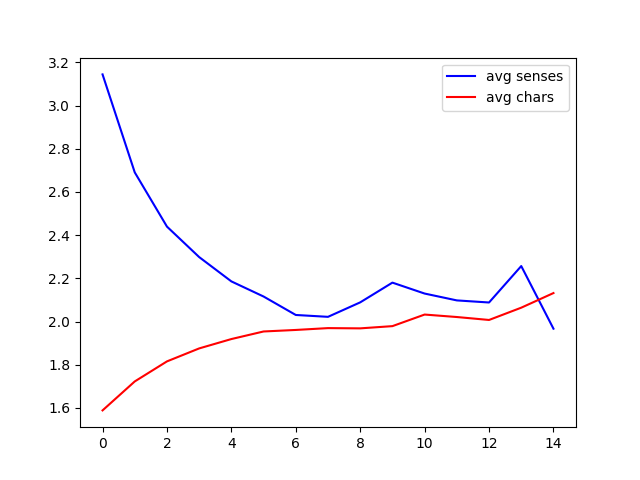
The number of senses (blue data points) clearly decreases as we move to less frequent ranges.
Average syllable count first approaches 2 and seems to stabilize there, before starting to climb again towards the right. This rhymes with another well-know observation: that Chinese “favors” an even number of syllables, which for most dictionary words means precisely 2.
Above the 6,000 mark (i.e., at lower frequencies) we can observe larger fluctuations in both plotted values. This is natural: in this region, CHDICT’s coverage becomes very sparse, which boosts the randomness inherent in these statistical patterns.